Обработка естественного языка (Natural Language Processing, NLP) объединяет технологии машинного обучения и лингвистику, причем и гуманитарную, и математическую её часть. В самом широком смысле, задачи NLP — это не только непосредственно обработка, но и понимание, и синтез текста или речи. Все эти задачи, от распознавания до генерации, сегодня стали главной темой искусственного интеллекта и вообще повсеместных трендом. Это видно и по заголовкам новостей, и по количеству научных статей, выходящих ежедневно. НТР следит за этим постоянным потоком новых алгоритмов, архитектур и подходов, и выделяет самые интересные работы и актуальные направления.
Особенности понимания синтаксиса человеческой речи.
Человеческое понимание языка остается ориентиром и пока недостижимой целью для языковых моделей. При всей небезошибочности первого и при всех невероятных успехах последних. Например, человеку обычно не составляет труда однозначно трактовать двусмысленные фразы исходя из контекста. Более того, мы с удовольствием используем такие каламбуры в шутках разного качества. Самый известный пример в английском: “Time flies like an arrow; Fruit flies like a banana”.
Д. Да
Я
Человек скорее всего после некоторых раздумий поймёт это как “Время летит как стрела, мухи любят банан”. Яндекс переводчик понимает эту фразу так: “Время летит как стрела, фрукты разлетаются как бананы”. Google translator демонстрирует зоологическую эрудированность: “Время летит как стрела; Фруктовые мушки, как банан”, а ChatGPT предлагает “Время летит как стрела; Мухи на фруктах летают как бананы”. В общем, никто не справился.
В отличие от LLM человек понимает (или чувствует) структуру предложения, его синтаксис. Это и помогает различать мух и фрукты. Поэтому возникает логичное желание обучить синтаксису языковые модели. В 2016 году предлагались синтаксические языковые модели (SLM), в основе которых было совместное распределение токенов и синтаксической структуры (статья). Теоретические основы восходят к работам Елинека и Лафферти из IBM Research (статья 1, статья 2) и Марка Паскина из Калифорнийского университета в Беркли (статья). SLM показывали хорошие результаты, но плохо масштабировались, поэтому с 2016 года они не обрели особого успеха. Сейчас началась вторая волна SLM на фоне успехов трансформеров, которая пытается объединить качество SLM и масштабируемость LLM.
Tree-Planted Transformers
В Токийском университете предложили архитектуру Tree-Planted Transformers (TPT), в которой синтаксические деревья “сажают” в модули внимания в трансформерах. Такие “рощи-трансфомеры” обучают на небольшом количестве деревьев, а затем масштабируют на большие корпусы текстов.
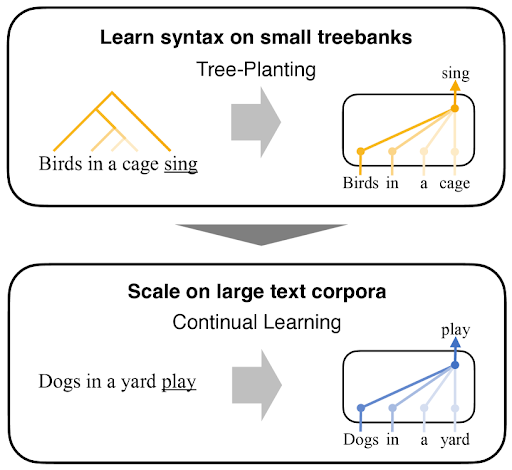
Слабое место SLM — само её пространство, так как моделируется совместное распределение (слов и синтаксиса). Поэтому авторы TPT нацелились на то, чтобы создать некоторую синтаксическую надстройку над трансформером, которая не тронула бы его модельное пространство.
Для этого сначала предлагают использовать двумерный аналог синтаксического расстояния. В одномерном предполагается расстояние между соседними токенами, а в двумерном рассматриваются все пары слов. Например, для фразы “birds in a cage sing” будут рассчитаны синтаксические расстояния для всех пар слов: “birds in”, “birds a”, “birds cage” и так далее.
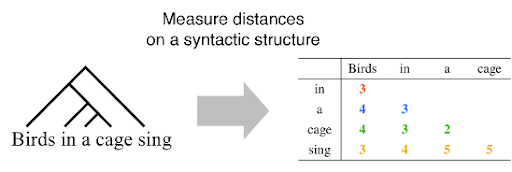
Из этой матрицы D получается матрица S, которая, собственно, контролирует веса внимания трансформера. В расчет S входят экспоненты, которые обеспечивают затухание по мере увеличения расстояния между словами.
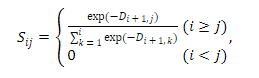
Это почти позволяет масштабировать SLM до большой модели, но остается только решить вопрос с тем, что инференс должен происходить без дополнительного парсера, который выполняет синтаксический анализ.
Этого авторы предлагаются добиться с помощью функции потерь. Используется расстояние Кульбака — Лейблера между матрицей контроля и матрицей весов внимания. Внимание перед этим пересчитывается с субтокенов до уровня токенов. Такая функция рассчитывается для каждого посаженного дерева, а затем усредняется и суммируется с лоссом предсказания следующего слова. Таким образом контроль за весами внимания встроен неявным образом.
Generative Pretrained Structured Transformer
Другой подход появился в марте этого года. Вновь предлагается объединить архитектуру трансформеров и SLM, но в этот раз без контроля (unsupervised). Обычно в таком варианте синтаксическое дерево строится с помощью однонаправленной модели (в предыдущей статье — тоже), то если проход осуществляется один раз справа налево. Из-за этого асимметричного процесса ветвление дерева не будет непредвзятым. Поэтому Generative Pretrained Structured Transformers (GPST) состоит из двух частей: сначала структурная модель проводит синтаксический анализ с помощью двусторонней функции потерь, а затем уже происходит генерация с однонаправленной моделью.
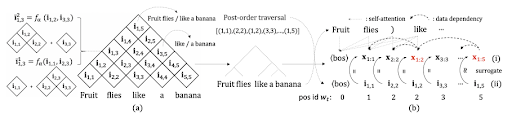
Этот подход повторяет ЕМ-алгоритм. На E-шаге создается синтаксическое дерево. На M-шаге оптимизируется совместная целевая функция на основе этого дерева. Поиск дерева происходит с помощью inside-outside алгоритма. Сначала внутренний проход — рассчитываются составные репрезентации для всех пересечений. Например fruit flies/like a banana, like/ a banana. Затем таким же образом внешний проход, но в другую сторону.
Представления, рассчитанные на внутреннем проходе, передаются как суррогат на вход трансформеров генеративной модели. Таким образом появляется возможность параллельного обучения всей архитектуры. После того, как дерево построено, одновременно обновляются параметры генеративной и структурной модели.
Интерпретируемость языковых моделей и что из неё следует
Black box AI is bad AI — гласит слоган исследовательской группы Pr(AI)2R (Practical AI Alignment and Interpretability Research). Её основал в 2023 году стэнфордский автор Аттикус Гигер (Atticus Geiger). Своей миссией группа считать превратить AI в “хороший AI”, то есть сделать его интерпретируемым.
Пока авторы выпустили три работы: Rigorously Assessing Natural Language Explanations of Neurons (лучшая статья 2023 по версии BlackBoxNLP), в которой попытались провести интерпретацию на уровне нейронов, Linear Representations of Sentiment in Large Language Models, где исследовали репрезентацию настроения в LLM и RAVEL: Evaluating Interpretability Methods on Disentangling Language Model Representations, где представили бенчмарк для оценки интерпретируемости. Есть и более ранние работы Гигера, в частности, он предложил исследовать внутренности LLM с помощью интервенций (изменения внутренних состояний). Суть его проста: если зафиксировать скрытое состояние, и выход модели поменяется так, как будто какой-либо компонент производил это состояние, то это даёт нам право установить причинно-следственную связь. Но тут расскажем о том, к каким конструктивным идеям приводит исследование интерпретируемости. Как говорится, критикуешь — предлагай.
Работы по интерпретируемости LLM приводят к выводу — скрытые состояния трансформера скрывают в себе много семантической информации. Именно они, а не веса. Опираясь на это авторы из Стэнфорда, в том числе и Гигер, пришли к гипотезе — донастройка модели должна модифицировать не веса, а скрытые состояния. Да, обновление небольшой доли весов LLM действительно позволяет эффективно донастроить её под нужную задачу, и эта мысль породила успешные и ставшие классическими LoRA и DoRA, но если учесть интерпретируемость, то результаты оказываются ещё лучше.
Новый метод авторы назвали по аналогии с PEFT (Parameter-efficient finetuning) — ReFT, Representation Finetuning (статья). Он основан на тех самых интервенциях, которые предложил Гигер. Модифицировать будем не веса, а прямо самые скрытые состояния. Интервенция (I) состоит из трёх компонентов — собственно функции интервенции (Ф) и своего рода координат L и P. Первая “координата” указывает на то, какой слой скрытый состояний мы изменяем, а вторая — какие из токенов.
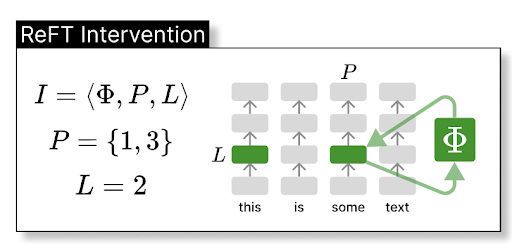
На примере с картинки выше интервенция касается только репрезентаций двух токенов (1 и 3) со слоя 2. Другие состояния при этом не затрагиваются. Это тоже важное отличие от PEFT методов, в которых обновляются все внутренние состояния. Ф забирает значение состояния сразу же, как только оно посчитано и возвращает в то же место. То есть на следующий слой подаётся уже измененное состояние.
Этот подход определяет сразу целое семейство методов. Один из возможных методов реализовали сами авторы в той же работе. Это Low-Rank Linear Subspace ReFT (LoReFT). Функция интервенции в этом случае содержит три обучаемых параметра — две матрицы R и W, и вектор b
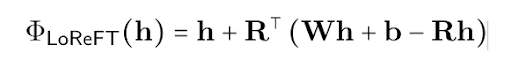
В экспериментах с LoReFT изменяли только состояния для двух первых и двух последних токенов. Остальные не трогали. В блоге авторы признаются, что вообще-то не ожидали большого успеха от метода. Интерес был скорее теоретический, с точки зрения интерпретируемости. А вышло, что LoReFT обошла текущий state-of-the-art
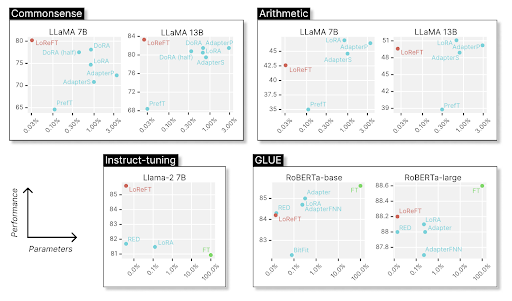
Что же из этого следует? Во-первых, обнаружилось, что интервенция во выходные токены влияет на токены всех поколений. То есть можно контролировать все поколения, поместив несколько начальных токенов в нужные состояния. Например, на картинке сверху на графике для instruct-tuning, LoReFT обошла текущего лидера, с помощью интервенции в 4 токена 4 первых слоев. Во-вторых, ReFT даёт новые инсайты для дальнейшего изучения интерпретируемости. Пока авторы делают такой вывод, что возможно сопоставлять нейроны каким-то словам вообще не имеет смысла. Возможно, у них нет никакой “специализации”, точнее есть, но меняется с каждым новым входным запросом. Что еще более важно, то, что кодируют нейроны, зависит от исходных вычислений, в которых они участвуют.
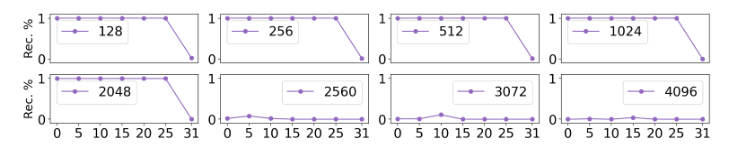
Почему LoReFT работает? Иронично, но авторы пока не очень понимают, снова получается black box. Но надеются понять из экспериментов — изучать численные пределы и из этого попробовать выяснить секрет действия. Например, авторы взяли один промпт на английском и обучали интервенции восстанавливать начало Алисы в стране чудес. То есть пытались проверить сколько слов может удержать одна интервенция, изменяя количество слоёв и токенов. Оказалось — до 2048 слов.
Чтобы легче было перейти с PEFT на ReFT, авторы создали библиотеку pyreft и приглашают всех её использовать.