Почти всегда статьи по ИИ содержат в конце таблицы с бенчмарками и словами, что такая-то новая модель обошла в каких-то задачах какие-то старые модели и даже сам GPT. Но разработки в сфере искусственного интеллекта обязательно сопровождаются исследованиями того, где вообще лежат границы применения ИИ — с точки зрения технологий, этики и даже философии.
Например, в последний год или несколько лет мы часто спорим насчет того, что такое AGI или world model. Последняя концепция впервые появилась, наверное, несколько десятков лет назад, но на новый уровень её вывел Ян Лекун. Как сделать, чтобы машины обучались настолько же эффективно, как люди или животные? Как машины могут обучиться репрезентациям и планировать действия на нескольких уровнях абстракции? Для этого, по мнению Лекуна, машине нужна такая же внутренняя модель мира, которая есть у животных. Когда в 2022 году он высказался о своем дальнейшем видении AI, вопросов было больше чем ответов. С тех пор концепция world model постепенно вошла в оборот, хотя до сих пор не совсем понятно, что же имеется в виду. Но тем не менее, что-то, что называют world model появляется. Приведем несколько примеров.
LAW. Авторы из Калифорнийского университета в Сан-Диего и Университета Джона Хопкинса объединили концепции языковой (Language), агентной (Agent) и мировой (World) моделей в один “закон” — LAW (статья). Отталкивались они от того, что LLM, даже достигнув колоссальных успехов и став самым продвинутым примером искусственного интеллекта, легко ошибаются в самых простых рассуждениях и планировании.
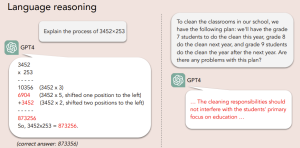
И это не похоже на что-то, что можно решить, в очередной раз увеличив размер модели. Это отражение фундаментальных ограничений: естественный язык по своей природе неоднозначен и неточен, и потому во многих ситуациях он неэффективен, как инструмент рассуждений. Когда человек говорит или пишет, он опускает гигантский пласт важнейшего контекста — начиная от собственного психологического состояния заканчивая общим здравым смыслом. LLM же генерирует текст лишь формально, не опираясь на физический, социальный или ментальный опыт. Другими словами, человек опирается на некую модель мира, какой бы она ни была, и формирует свои представления. На их основе человек принимает решения — этим руководит “агентная модель”. Примерно такую концепцию авторы и предлагают перенести на искусственный интеллект.
Так как в этом поле пока нет устоявшихся определений и каждый использует что-то своё, сейчас будем использовать определения авторов статьи.
Модель мира — ментальные репрезентации, которые использует агент, чтобы понимать и прогнозировать внешний мир
Агентная модель — включает в себя мировую модель и другие важные компоненты, в том числе цели агента, его убеждения насчет текущего состояния мира и других агентов.
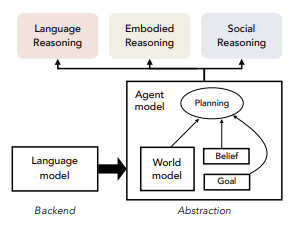
Языковая модель в концепции LAW — это бэкендная часть. Рассуждения должна строить не сама LLM (которая не всегда безупречна в этом), а агентная и мировая модели. Они, по мнению авторов, обладают большей степенью абстракции и могут учитывать вещи, важные в человеческих рассуждениях: убеждения, ожидания последствий, стратегию.
Чтобы обучится физическому миру, одного только текста, конечно, не достаточно. Мировая модель должна будет обучаться на человеческих демонстрациях, взаимодействии с человеком и обязательно на реальном физическом опыте. И тут происходит приятное совпадение, как когда две группы строителей роют тоннель с двух разных входов и наконец встречаются посередине. Для бурного развития AI-роботики не хватает ровно того же — реальных физических данных для обучения. В 2021 году OpenAI, не привлекая внимания, приостановила команду роботехники просто из-за того, что не было данных, на которых можно было учить роботов (об этом рассказывал руководитель направления Войцех Заремба в подкасте). Google Deepmind поступил по-другому и создали AutoRT (статья, блог), которая насобирала тысячи реальных примеров, в которых роботы выполняют различные задания.
AutoRT. AutoRT использует готовые базовые модели — модель зрения осматривает ситуацию и положение и описывает что видит, LLM генерирует задания, еще одна LLM отбирает наиболее подходящие из них и отдает на исполнение роботу.
Авторы запустили флот из 20 роботов (система может работать и на произвольном количестве) на семь месяцев в 4 разных здания своего кампуса. Пока на фоне продолжали свои занятия сотрудники гугл, роботы разъезжали по офису и сами искали себе задания. Чуть подробнее о внутренностях AutoRT: VLM составляет в свободной форме описание окружения, перечисляет объекты, которая видит робот. Например “вижу пачку чипсов и губку”. Языковая модель предлагает несколько заданий, например “открой чипсы”, “протри стол” или “положи пачку на стол”. Эти задания отправляются на суд другой LLM, которая действует в соответствии с конституцией. Она решает, какие из этих заданий робот выполнить не может, какие может только с помощью человека, а с какими справится сам. Это нужно для того, чтобы AutoRT могла безопасно работать в более разнообразной обстановке с неизвестными объектами.
Вернёмся еще раз к той самой конституции, по которой отбираются подходящие задания. Она по сути заменяет файнтюнинг сводом правил. Сами правила делятся на три категории. Во-первых, базовые правила — примерно те же, что и в трех законах робототехники Айзека Азимова:
Робот не может принести вред человеку
Робот должен защищать самого себя, если это не противоречит первому пункту
Робот должен подчиняться командам человека, если это не нарушает первые два пункта.
Во-вторых, правила безопасности, которые запрещают задания с живыми существами, острыми объектами и электричеством. В-третьих, физические ограничения — единственная рука и запрет на поднятие чего-то тяжелее книги.
Иногда сотрудники мешали выполнить роботу задание (например, клали пачку чипсов обратно в ящик). В итоге за семь месяце флот роботов собрал 77 000 уникальных заданий.
Еще одна, почти философский проект, The Platonic Representation Hypothesis от исследователей из MIT, в которой цитируют не только Open Ai и ChatGPT, но и Платона и Льва Толстого. Гипотеза авторов заключается в следующем: нейронные сети разных архитектур, обученные на разных данных и для разных целей, сходятся. Причем сходятся к статистической модели реальности.
Получается, что все модели, большие и маленькие, языковые, графические и мультимодальные, не просто показывают свою часть одной и той же модели реальности, но еще и в перспективе приведут к вообще одному отображению. Будет ли это AGI, будет ли та та модель мира, о которой говорил Лекун — в явном виде авторы эти вопросы не упоминают, но вывод напрашивается сам.
Итак, допустим, у нас есть реальный мир. На картинке снизу реальный мир состоит из синего конуса и красного шара и обозначается Z. Его можно воспринимать или измерять с помощью разных сенсоров. Получатся некоторые модели (в попперианском смысле) реального мира. Например, камера Х снимает Z и получает картинку, а Y дает текстовое описание. Эти проекции, или отображения, или репрезентации хоть и совершенно разные по форме и содержанию, получаются из одной и той же реальности Z и в этом смысле разумно полагать, что они будут синхронизированы.
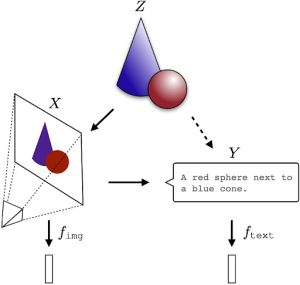
Теперь чуть ближе к статистическим моделям. Алгоритмы обучаются на этих отображениях и строят на них статистические модели, которые соответствуют нужной цели. Но чем больше модель, тем больше информации должны содержать в себе отображения, поэтому их стройное равнение на Z должно быть всё быстрее по мере масштабирования.
Авторы приводят три возможных, но не взаимоисключающих обоснования сходимости. Это пока не доказательства, а общие рассуждения, хотя и основанные на математическом подходе. Даже не так — это еще три гипотезы, которые объясняют принципы действия первой гипотезы.
Первый вариант — сходимость объясняется обобщением заданий. Каждая точка обучающих данных и каждое задание вносит свои дополнительные ограничения в модель. То есть по мере масштабирования тех и других количество отображений, которые будут удовлетворять ограничениям будет всё меньше.
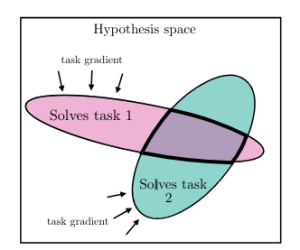
Другими словами, чем “общее” модель, тем меньше у неё будет возможных решений. Результаты последних лет доказывают, что чем больше данных, тем лучше результат. Отсюда вывод следующий: когда данных будет достаточно много (скажем, весь интернет и все живые физические параметры), то модель сойдется к очень маленькому набору решений. Можно было бы сказать, что к единственному решению, но это не позволяет сделать неустранимая неопределенность мира.
Второй вариант — сходимость объясняется емкостью модельного пространства. Здесь имеются в виду набор функций, среди которых модель с помощью обучения выбирает подходящую. Чем больше это пространство, то эффективнее будет поиск оптимума. Другими словами, большие модели (даже разной архитектуры) с большей вероятностью сойдутся к одному отображению, чем маленькие.
Третий вариант — стремление к простоте. Можно предполагать, что репрезентация собаки, которую построит модель с 1М параметров будет отличаться от той же собаки в представлении 1В модели. Что помешает большой модели обучиться слишком сложным и детализированным отображениям? Нейросети стремятся к более простым решениям, которые соответствуют задаче. И чем больше модель, тем сильнее это стремление. Оно может исходить из заданной в явном виде функции регуляризации, но и без неё предпочтения будут отдаваться самому простому решению из подходящих.
Хорошо, модели ИИ будут умнеть и сходится к чему-то одному. Теперь, главный вопрос — к чему. Под статистической моделью реальности, о которой мы уже упомянули в начале, авторы предполагают набор дискретных событий из некоторого (неизвестного) распределения P(Z). Каждое событие можно наблюдать по-разному. “Наблюдение” — это биекция с определенной (известной) функцией. Функция распределения P(Z), если её каким-то образом узнать, и будет содержать модель мира. Возьмем модель, которая будет учиться определять события, происходящие вместе, то есть определять PMI, pointwise mutual information, поточечную взаимную информацию.
Модель мира состоит из биекций, а они сохраняют вероятности. Выходит, что какой бы модальности ни была модель, ядро отображения будет то же, которое определяет заданную в P(Z) статистику.
Авторы привели несколько примеров, когда согласованные репрезентации выходят у моделей разной архитектуры, причем это действительно становится заметнее по мере увеличения размеров и перфоманса. Тут и пригодился Толстой, которого перефразировали так: “все сильные модели сильны одинаково, а каждая слабая модель слаба по-своему”
Какие последствия у этой, пока теоретической, но претендующей на фундаментальную истину сходимости? Во-первых, получается, что масштабирование моделей, может, конечно, и достаточный, но вовсе не самый эффективный способ. Если совершенно разные модели сходятся к одному, то означает ли это, что “scale is all you need” ? Авторы уверены, что нет.
Во-вторых, обучающие данные могут (и даже наверное должны) быть мультимодальными. Допустим, у вас есть набор изображений и предложений. Если озвученные гипотезы верны, тогда и языковые и графические данные должны помочь найти лучшее отображение. То есть, чтобы обучить лучшую языковую модель, нужно обучать её и на картинках тоже. Впрочем, эта практика уже действительно набрала обороты.
Причём здесь Платон? Тут авторы имеют в виду платоновскую пещеру, её узники видят лишь тени на стенах, которые отбрасывает реальный мир. В нашем случае тени — это обучающие данные, то, что доступно нам, узникам пещеры. Платон использовал эту аллегорию, чтобы показать, что люди горько ошибаются, полагая, что могут по этим теням судить о реальном мире за пределами пещеры. Но если продолжать аналогию, то авторы как раз и пытаются доказать, что разные тени сходятся к реальному миру. Платон бы, наверное, поспорил, что это иллюзия. Но это уже совсем другая история.